本プロジェクトではPythonを活用し、機械学習を用いた複数のモデルを比較検証することで、売上予測の精度の向上と業務効率化を目指しました。
背景として、現在多くの企業ではマーケティング運用においてマニュアル作業やExcelを用いたシンプルな回帰モデルで売上予測を実施しています。
しかしこれらの方法では精度の向上や一連のプロセス自動化に限界があるため、Pythonを活用した売上予測の自動化が有効になるのではと考えました。
Githubを見る
サンプルデータの概要
- データ内容: アルコール飲料会社の売上および広告出稿データ
- 期間: 過去2年間の週次データ
- 主要メトリックス:
- 売上
- デジタル広告費
- OOH(屋外広告)
- テレビCMのGross Rating Points (GRP)
- 紙媒体広告の支出
比較したモデルと選定理由
各モデルは、それぞれ異なる特徴と強みを持っており、売上予測への適用可能性を検証しました。
- Linear Regression (OLS):
- 売上と外部変数間の基本的な関係性をモデル化するシンプルな手法です。
- 選定理由: モデルの基礎として、他の高度な手法との比較対象となるため。
- Prophet:
- Facebookが開発した、強い季節性や外部要因を考慮した時系列予測モデルです。
- 選定理由: 季節性が強いデータに対し、直感的なパラメータ調整が可能な点が魅力です。
- LightGBM:
- 変数間の複雑かつ非線形な相互作用を効率的に捉える機械学習モデルです。
- 選定理由: 大規模データや非線形性が強い場合に、予測精度が向上する可能性が高いため。
- SARIMAX (Seasonal ARIMA with external regressors):
- 従来のARIMAモデルに外部説明変数を組み合わせ、季節効果と外部影響を同時に捉える手法です。
- 選定理由: 時系列の動向に加え、外部要因も同時に取り入れることで、より現実的な予測が可能となるため。
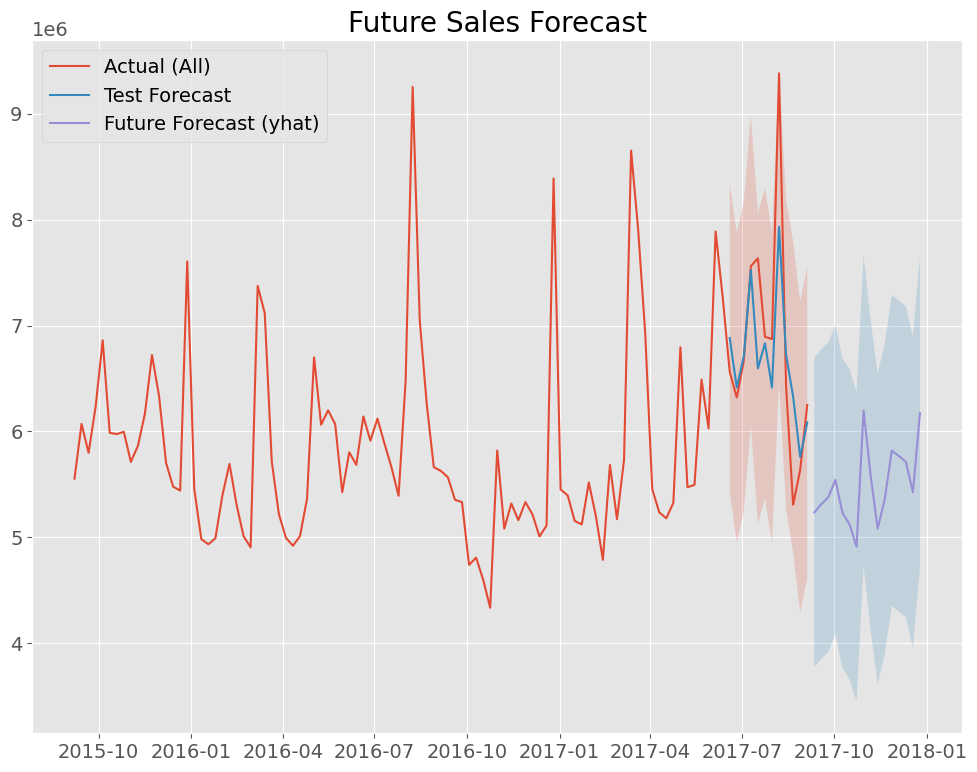
パフォーマンス比較
各モデルの予測性能は、以下の評価指標を用いて比較しました。なお、各指標は数値が小さいほど予測精度が高いことを示し、誤差の許容範囲は対象データの特性や業界標準によって変動するため、ここでは一般的な目安を示しています。
Root Mean Squared Error (RMSE):
- 概要: 予測値と実際の観測値との差(誤差)の二乗平均の平方根を算出します。
- 詳細:
- 大きな誤差に対してより大きなペナルティを与えるため、極端な外れ値の影響を受けやすい。
- 元のデータと同じ単位で表現されるため、直感的な理解が可能です。
- 許容範囲の目安:
- 一般的には平均売上の約5〜10%以下が望ましいが、データのスケールに依存します。
Mean Absolute Error (MAE):
- 概要: 予測値と実測値との差の絶対値の平均を求める指標です。
- 詳細:
- プラスとマイナスの誤差が相殺されないため、全体の平均誤差の大きさが明確に分かります。
- 極端な誤差の影響が抑えられるため、実用的な誤差の評価に適しています。
- 許容範囲の目安:
- 対象データの平均値に対して、誤差が5〜10%以内であれば高精度と評価されることが多いです。
Mean Absolute Percentage Error (MAPE):
- 概要: 予測誤差を実測値に対する割合(パーセンテージ)で表し、その平均値を算出します。
- 詳細:
- 異なるスケールのデータでも比較が容易で、「全体の何パーセントの誤差か」を直感的に理解できます。
- 実測値がゼロに近い場合は、誤差が過大評価される可能性があるため注意が必要です。
- 許容範囲の目安:
- 一般的にはMAPEが10%未満なら非常に良好、10〜20%なら良い、20〜50%なら許容範囲、50%以上は改善が必要とされます。
洞察と考察
本プロジェクトでは、グラフやチャートを用いて各モデルの予測結果や誤差の分布を視覚化し、モデルごとの強みと弱みを明確にしました。これにより、データのトレンドや季節性、外れ値の影響などを直感的に把握できるようになっています。
さらに、より長期のデータや異なるマーケティングチャネルからのデータを取り入れることで、モデルの汎用性と精度の向上を目指します。
また、他の予測モデルの導入や各モデルのハイパーチューニングの再検討を通じて、予測精度をさらに高める作業も実施します。